
Los motores de búsqueda tradicionales ( Google , Yahoo, Bing , etc.) sólo ofrecen acceso a una pequeña parte de lo que existe online, lo que se ha
comenzado a llamar la Web superficial o visible.
Lo que resta, la Web
profunda, es un amplío banco de información ubicado en catálogos,
revistas digitales, blogs, entradas a diccionarios y contenido de sitios
que demandan un login (aunque sea gratuito), entre otros tipos de
contenido que no aparecen entre los resultados de una búsqueda
convencional.
Diferencias entre Web visible (superficial) y Web invisible ( profunda)
La Web visible comprende todos aquellos sitios cuya información puede
ser indexada por los robots de los buscadores convencionales y
recuperada casi en su totalidad mediante una consulta a sus formularios
de búsqueda.
Características principales
- Su información no está contenida en bases de datos
- Son
de libre acceso
- No hay que registrarse para acceder
- Están
formadas por páginas Web estáticas ,páginas o archivos con una URL fija y
accesibles desde otro enlace.
La Web invisible, en cambio , comprende toda la información disponible en Internet
que no es recuperada interrogando a los buscadores convencionales.
Generalmente es información almacenada y accesible mediante bases de
datos, que Si bien el 90% de estas bases de datos están públicamente
disponibles en Internet, los robots de los buscadores solamente pueden
indicar su página de entrada (homepage). La información almacenada es
por consiguiente "invisible" a estos.
Para
poder acceder a la información disponible en las bases de datos hay que
hacer consultas a través de páginas dinámicas ( ASP , PHP ,...) es decir
páginas que no tienen una URL fija y que se construyen en el mismo
instante (temporales) desapareciendo una vez cerrada la consulta.
Según Lluis Codina:" Internet invisible esun nombre claramente inadecuado para referirse al sector de sitios y de páginas web que no pueden indizar los motores de búsqueda de uso público. Debería denominarse, en realidad, la web "no indizable", lo cual es un término mucho más adecuado".
Chris Sherman y Gary Price en su libro La Web Invisible (2001) identifican cuatro tipos de contenidos invisibles en la Web.
- Web opaca
- Web privada
- Web propietaria
- Web realmente invisible
La Web opaca: Se compone de archivos que no están incluidos en los motores de búsqueda por alguna de estas razones:
- Extensión de
la indización: por economía, no todas las páginas de un sitio son indizadas
en los buscadores.
- Frecuencia de
la indización: los motores de búsqueda no tienen la capacidad de indizar todas
las páginas existentes; diariamente se añaden, modifican o desaparecen muchas
y la indización no se realiza al mismo ritmo.
- Número máximo
de resultados visibles: aunque los motores de búsqueda arrojan a veces un gran
número de resultados de búsqueda, generalmente limitan el número de
documentos que se muestran (entre 200 y 1000 documentos).
- URL’s
desconectados: las generaciones más recientes de buscadores, como Google
presentan los documentos por relevancia basada en el número de veces que
aparecen referenciados o ligados en otros. Si un documento no tiene una liga en
otro documento será imposible que la página sea descubierta, pues no habrá
sido indizada.
La web privada: Se compone de archivos que no están incluidos en los motores de búsqueda por alguna de estas razones:
- Las páginas están protegidas por contraseñas (passwords).
- Contienen un archivo “robots.txt” para evitar ser indizadas.
- Contienen un campo “noindex” para evitar que el buscador indice la parte correspondiente al cuerpo de la página.
Este segmento de la web no representa una gran pérdida en términos de
valor de la información que contiene, ya que se trata, en general, de
documentos excluidos deliberadamente por su falta de utilidad.
La Web propietaria:
Incluye aquellas páginas en las que es necesario registrarse para tener
acceso al contenido, ya sea de forma gratuita o de pago. Se dice que al
menos 95% de la Web profunda contiene información de acceso público y
gratuito.
La Web realmente invisible: Se compone de páginas que no pueden ser indizadas por limitaciones técnicas de los buscadores, como las siguientes:
- Páginas web que incluyen formatos como PDF , PostScript , Flash , Shockwave, programas ejecutables y archivos comprimidos.
- Páginas generadas dinámicamente, es decir, que se generan a partir de datos que introduce el usuario.
- Información almacenada en bases de datos relacionales.
Hay que tener en cuenta que:
- Algunos buscadores recuperan archivos PDF y páginas con imágenes, aunque de forma limitada.
- Es relativamente sencillo llegar hasta la “puerta” de las bases de datos con contenido importante.
- Existen motores avanzados capaces de realizar búsquedas directas simultáneas
en varias bases de datos a la vez; y aunque la mayoría requieren de
pago, también ofrecen versiones gratuitas.
- El contenido que se
genera en tiempo real pierde validez con mucha velocidad, salvo para
análisis históricos; es relativamente sencillo llegar hasta la “puerta”
de los servicios que ofrecen información en tiempo real.
- El contenido que se genera dinámicamente interesa únicamente a ciertos usuarios con características específicas.
- Es relativamente sencillo llegar hasta la “puerta” de los servicios que ofrecen contenido generado dinámicamente.
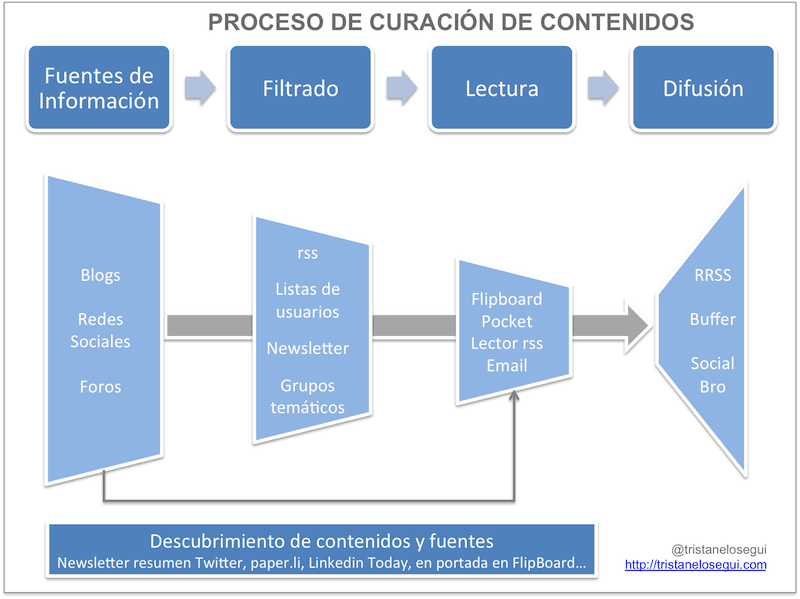
Herramientas de búsqueda en la web profunda
En
general han mejorado su desempeño en los últimos años,
permitiendo un mayor nivel de precisión en las búsquedas y ofreciendo los
resultados en formas cada vez más convenientes para el usuario.
Pero por
ahora, los buscadores comunes sólo pueden recuperar directamente la información
que se encuentra disponible en la web
y no aquella que se ofrece a través
de la web.
Desde
que se empezó a hablar de la web invisible los buscadores comunes han añadido
funcionalidades adicionales para la búsqueda en la llamada web profunda y han
surgido buscadores especializados en ese segmento de la web.
Los metabuscadores pueden presentar limitaciones respecto a las
posibilidades de búsqueda de cada buscador por separado. Por ejemplo, cuando la
búsqueda es sobre materiales o formatos especiales, resulta más práctico
sacar provecho de las opciones avanzadas de búsqueda de los buscadores y, si es
necesario, realizar búsquedas sucesivas en varios de ellos. En este sentido,
son más recomendables los directorios concentradores de buscadores.
Ejemplo: iBoogie, Fazzle, Ixquick, Search.Com
La mayoría
de los mecanismos que se usan para localizar recursos en la web profunda
consisten en directorios de recursos especializados, principalmente bases de
datos disponibles de forma gratuita en la red. El patrocinio de las
instituciones académicas en la elaboración de los directorios, particularmente
de los que son anotados, garantiza la cobertura y calidad de los recursos
compilados.
Directorios
CompletePlanet, Direct Search, HotSheet, IncyWincy, InternetInvisible, Librarians Index, Master Link List On the Internet, RefDesk.com, Webfile.com, Where to Do Research
Directorios anotados
AcademicInfo, Resource Discovery Network
Directorios de bases de datos
WebData.com
Las guías
de recursos especializados generalmente están elaboradas por bibliotecarios y
son una excelente herramienta de búsqueda y localización de recursos, además
de constituir un buen instrumento de aprendizaje en el uso de la información.
Ejemplo: About, LibrarySpot
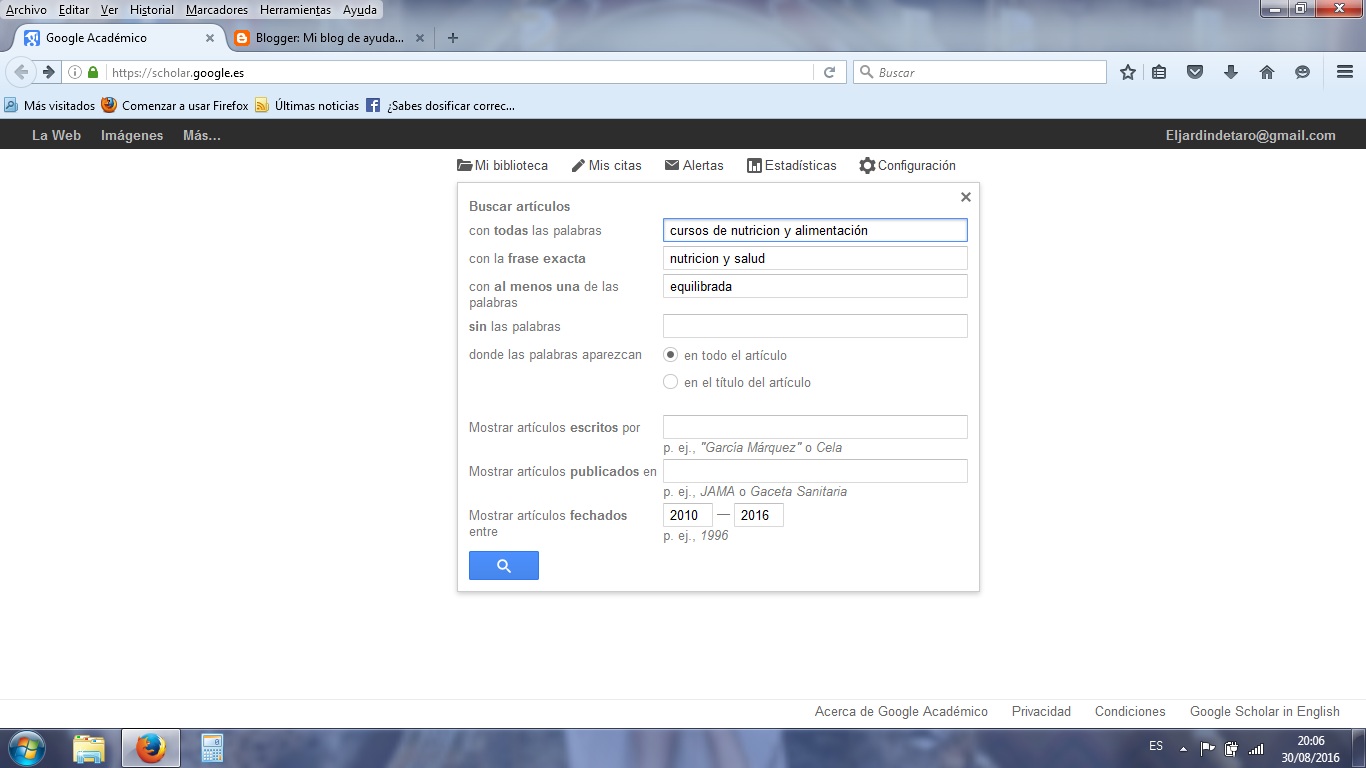
Como realizar una búsqueda en la web profunda
1- Información
especializada
·
Usar
las herramientas de búsqueda en la web profunda si buscamos información académica de calidad.
·
Usar
buscadores regionales especializados para localizar información originada
fuera de los Estados Unidos o en idiomas diferentes al inglés.
·
Usar
metabuscadores para realizar búsquedas en varios buscadores especializados
a la vez.
·
Usar
las opciones avanzadas de los buscadores para localizar imágenes o archivos
PDF o PostScript.
·
Usar
directorios concentradores de buscadores para realizar búsquedas avanzadas
sucesivas en varios de ellos.
3- Evaluación
de la información
·
Usar
directorios anotados para evaluar si los recursos disponibles en la web
profunda son útiles para la búsqueda
que estamos realizando.
·
Usar
directorios de bases de datos para conocer cuáles de ellas pueden
ofrecernos información útil para nuestras búsquedas.
4- Información
en bases de datos
·
Usar
guías, directorios o motores avanzados si la información que buscamos
puede estar en una base de datos.












{kind=link}